Querying the Datasets
Contents
[hide]Semantic Media Wiki Queries
The data in the wiki can be queried and embedded within the wiki by Semantic Media Wiki (SMW) queries. The queries refer to the Special:Categories and Special:Properties defined in the wiki.
Example: Get a List of Datasets (limit to 5)
{{ #ask: [[Category:Dataset_(L)]]
| mainlabel=Datasets
| format=broadtable
| limit=5
}}
| Datasets |
|---|
| A7.Oppo.2005 |
| Afr-ColdAirCave.Sundqvist.2013 |
| Afr-LakeMalawi.Powers.2011 |
| Afr-LakeTanganyika.Tierney.2010 |
| Afr-P178-15P.Tierney.2015 |
| ... further results |
Example: Get a List of Datasets that have paleo data based on d18O Proxy (limit 5)
{{ #ask: [[Category:Dataset_(L)]] [[IncludesPaleoData_(L).FoundInMeasurementTable_(L).IncludesVariable_(L).ProxyObservationType_(L)::D18O]]
| ?IncludesPaleoData_(L)=PaleoData
| format=broadtable
| limit=5
}}
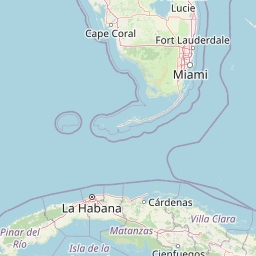
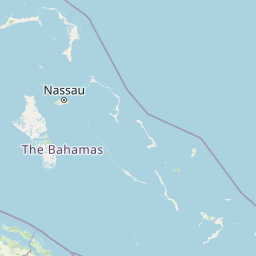
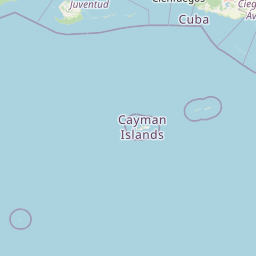
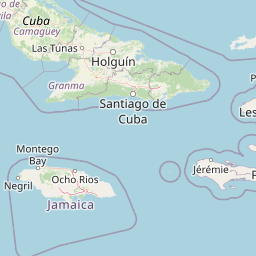
Example: Get a List of Datasets with archive type "Sclerosponge" and plot them on a map
{{#ask:
[[Category:Location_(L)]]
[[CoordinatesFor.IncludesPaleoData_(L).FoundInMeasurementTable_(L).IncludesVariable_(L).HasProxySystem_(L).ProxyArchiveType_(L)::Sclerosponge]]
| ?Coordinates
| ?CoordinatesFor
| ?Name_(L)
| showtitle=off
| maxzoom=14
| minzoom=1
| limit=500
| template=LiPDLocation
| format=leaflet
}}



SPARQL Queries
One can also make more complex queries using SPARQL to the wiki's triple store. The SPARQL endpoint is http://wiki.linked.earth/store/ds/query, and one can make queries by passing a query parameter with the text of the SPARQL query. The data can be returned in a variety of formats. The SPARQL queries refer to the Linked Earth core ontology terms found at http://linked.earth/ontology.
Note: The mapping between terms on the wiki and the ontology can be found at any wiki Property or Category page by looking at the "Imported from" value. For example, the property Property:ArchivedIn_(L) imports the term core:archivedIn from the ontology, where "core:" prefix refers to the linked earth ontology at http://linked.earth/ontology
Get Datasets that have paleo data based on d18O Proxy ( along with file names of the csv files )
PREFIX core: <http://linked.earth/ontology#>
PREFIX wiki: <http://wiki.linked.earth/Special:URIResolver/>
SELECT ?s ?pd ?table ?file
WHERE {
?s a core:Dataset .
?s core:includesPaleoData ?pd .
?pd core:foundInMeasurementTable ?table .
?table core:includesVariable ?var .
?var core:proxyObservationType wiki:D18O .
?table core:hasFileName ?file
}The following is a live URL that queries the SPARQL endpoint with the above query:
Get Datasets that have inferred variables with its calibration uncertainty less than 0.5
PREFIX core: <http://linked.earth/ontology#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?ds ?data ?v ?val
WHERE {
?v a core:InferredVariable .
?v core:calibratedVia ?calibration .
?calibration core:hasUncertainty ?unc .
?unc core:hasValue ?val .
FILTER (xsd:double(?val) < 0.5) .
?ds a core:Dataset .
?v core:foundInTable ?table .
?data core:foundInMeasurementTable ?table .
?ds core:includesPaleoData ?data
}The following is a live URL that queries the SPARQL endpoint with the above query:
Querying Linked Earth Data from another Program/Script
Since the endpoint at http://wiki.linked.earth/store/ds/query also allows one to make queries remotely, one can make queries programmatically from their programs and scripts using whichever language they are comfortable in.
Fetch all dataset names from the wiki
import json
import requests
url = "http://wiki.linked.earth/store/ds/query"
query = """PREFIX core: <http://linked.earth/ontology#>
PREFIX wiki: <http://wiki.linked.earth/Special:URIResolver/>
SELECT ?ds ?name
WHERE {
?ds a core:Dataset .
?ds core:name ?name
}"""
response = requests.post(url, data = {'query': query})
res = json.loads(response.text)
for item in res['results']['bindings']:
print (item['name']['value'])Fetch all dataset csv files given a dataset name
import os
import sys
import json
import requests
import urllib
datasetname = sys.argv[1]
print datasetname
endpoint = "http://wiki.linked.earth/store/ds/query" # Query Metadata
wikiapi = "http://wiki.linked.earth/wiki/api.php" # Fetch file data
query = """PREFIX core: <http://linked.earth/ontology#>
PREFIX wiki: <http://wiki.linked.earth/Special:URIResolver/>
SELECT ?data ?filename
WHERE {
?ds core:includesPaleoData ?data .
?ds core:name '""" + datasetname + """' .
?data core:foundInMeasurementTable ?table .
?table core:hasFileName ?filename
}"""
response = requests.post(endpoint, data = {'query': query})
res = json.loads(response.text)
for item in res['results']['bindings']:
fileid = item['filename']['value']
fileresponse = requests.post(wikiapi, params = {
'action': 'query',
'prop': 'imageinfo',
'iiprop' : 'url',
'format' : 'json',
'titles' : fileid
})
fileres = json.loads(fileresponse.text)
for pageid in fileres['query']['pages']:
fileitem = fileres['query']['pages'][pageid]
fileurl = fileitem['imageinfo'][0]['url']
print fileurl
filelib = urllib.URLopener()
filelib.retrieve(fileurl, os.path.basename(fileurl))Using Jupyter Notebook
The LinkedEarth team put together a Jupyter Notebook that allows fairly complex queries with no knowledge of coding required. All you need is Python v3+ and Jupyter Notebook installed on your computer. You can download the Notebook here.
See Also
- Coral Query: Learn how to search the database by archive type